
Originally published on https://selenachau.wordpress.com/2016/10/18/ruby-nokogiri-for-webscraping/ for the AAPB NDSR.
As part of the AAPB NDSR fellowship, we residents are afforded personal professional development time to identify and learn or practice skills that will help us in our careers. This is a benefit that I truly appreciate!
 Ruby... the jewels theme continues from Perl
Ruby... the jewels theme continues from Perl
I had heard of the many programming and scripting languages like Perl, Python, Ruby, and bash but really didn't know of examples that showed their power, or applicability. In the past month, I've learned that knowing the basics of programming will be essential in data curation, digital humanities, and all around data transformation and management. Librarians and archivists are aware of the vast amount of data: why not utilize programming to automate data handling? Data transformation is useful for mapping and preparing data between different systems, or just getting data in a clearer, easier to read format than what you are presented with. At the Collections as Data Symposium, Harriett Green presented an update on the HTRC Digging Deeper, Reaching Further Project [presentation slides]. This project provides tools for librarians by creating a curriculum that includes programming in Python. This past spring, the workshops were piloted at Indiana University and University of Illinois--my alma mater :0). I can't wait until the curriculum becomes more widely available so more librarians and archivists know the power of programming!
But even before the symposium, my NDSR cohort had been chatting about the amounts of data we need to wrangle, manage, and clean up in our different host sites. Lorena and Ashley had a Twitter conversation on Ruby that I caught wind of. Because of my current project at KBOO, I was interested in webscraping to collect data presented on HTML pages. Webscraping can be achieved by both Python and Ruby. My arbitrary decision to learn Ruby over Python is probably based on the gentle, satisfying sound of the name. I was told that Python is the necessary language for natural language processing. But since my needs were focused on parsing html, and a separate interest in learning how Ruby on Rails functioned, I went with Ruby. Webscraping requires an understanding of the command line and HTML.
- I installed Ruby on my Mac with Homebrew.
- I installed Nokogiri.
- I followed a few tutorials before I realized I had to read more about the fundamentals of the language.
I started with this online tutorial, but there are many other readings to get started in Ruby. Learning the fundamentals of the Ruby language included hands-on programming and following basic examples. After learning the basics of the language, it was time for me to start thinking in the logic of Ruby to compose my script.
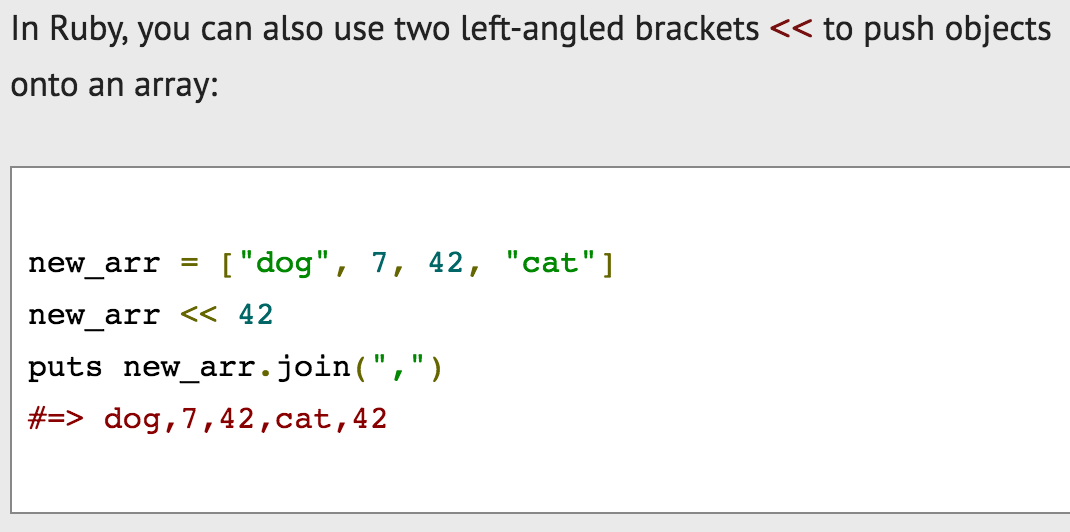
From: http://ruby.bastardsbook.com/chapters/collections/
Pieces of data are considered objects in Ruby. These objects can be pushed into an array, or set of data.[/caption] As a newbie Ruby programmer, I learned that there is a lot I don't know, there are better and more sophisticated ways to program if I know more, but I can get results now while learning along the way. For example, another way data sets can be manipulated in Ruby is by creating a hash of values. I decided to keep going with the array in my example. 
So, what did I want to do? There is a set of program data across multiple html pages that I would like to look at in one spreadsheet. The abstract of my Ruby script in colloquial terms is something like this:
- Go to http://kboo.fm/program and collect all the links to radio programs.
- Open each radio program html page from that collection and pull out the program name, program status, short description, summary, hosts, and topics.
- Export each radio program's data as a spreadsheet row next to its url, with each piece of information in a separate column with a column header.
My Ruby script and the resulting csv are on my brand new GitHub, check it out! The script takes about a minute to run through all 151 rows, and I'm not sure if that's the appropriate amount of time for it to take. I also read that when webscraping, one should space out the server requests or the server may blacklist you--there are ethics to webscraping. I also noticed that I could clean up the array within array data: the host names, topics, and genres still have surrouding brackets around the array. It took me a while to learn each part of this, and I also used parts of other people's scripts similar to my need. It also showed me that it takes a lot of trial and error. However, it also showed me that I could work with the logic and figure it out! There is a lot of data on web pages, and webscraping basics with a programming language like Ruby can help retrieve items of interest and order them into nice csv files, or transform and manipulate them in various ways. Next, I think I can create a similar script that lists all of a program's episodes with pertinent metadata that can be mapped to a PBCore data model, i.e. episode title, air date, episode description, and audio file location. Please share any comments you have! In a recent Flatiron School webinar on Ruby and Javascript, Avi Flombaum recommended these book titles to read on Ruby: The well-grounded Rubyist, Refactoring: Ruby edition, and Practical object-oriented design in Ruby. Learn Ruby the hard way comes up a lot in searches as well.